ゼータビッツ株式会社 前田 修吾 shugo@zetabits.co.jp
Rubyというスクリプト言語をご存知でしょうか。数年 前まではまだ一部の人々にしか知られていなかったこ の言語が、現在急速に普及しつつあります。すでに いくつかの書籍が出版されていますし、雑誌などでも 取り上げられています。しかし、興味はあるけれども 実際に使ったことはないという方もまだ多いのではな いでしょうか。
そこで、本稿ではRubyの特長について簡単に説明した 上で、Ruby/eRubyによるCGIプログラミングについて 解説します。
Rubyはまつもとゆきひろ氏によって設計・実装された スクリプト言語です。「オブジェクト指向スクリプト 言語」と紹介されることが多いように、本格的なオブ ジェクト指向機能を備えています。
ではRubyとは具体的にどのような言語なのでしょうか。 以下ではRubyのいくつかの特長について見てみること にします。あまり詳しい説明はしませんので、わから ない部分は適当に読みとばしてください。
README.jpにはRubyの特長として「シンプルな文法」 という項目が挙げられています。たとえば、Rubyで "hello world"と出力するプログラムは、
print "hello world"
と、実にシンプルです。
しかし、Rubyの文法を詳しく見てみると、実はなかな か複雑であることがわかります。たとえば、先程の一 行のプログラムを正確に説明すると、
暗黙のレシーバselfと引数の括弧が省略された printメソッドの呼び出しである。この場合はトッ プレベルであるためselfはObjectクラスのインスタ ンスであるmainオブジェクトであり、Objectの printメソッドが呼ばれる。ただし、ユーザがオー バーライドしていないかぎり、printメソッドは Objectクラスではなく、Objectクラスにインクルー ドされたKernelモジュールで定義されている。
となります。(この部分の意味がわからなくても全然 構いません。)ではRubyでプログラムを書くのは大変 なのではないかと思われるかもしれませんが、そんな ことはありません。
たとえば、SchemeというLispの方言は非常にシンプル でエレガントな文法を持っています。筆者自身Scheme にはじめて触れた時は非常に感動したのですが、普段 使っているのはSchemeではなくRubyです。Schemeの言 語自体はたしかにシンプルなのですが、Schemeによっ て書かれるプログラムの方はRubyのプログラムよりも 複雑に感じられます。(これは筆者の無理解と偏見に よるものかもしれません。鵜呑みにせずご自分で Schemeに触れて確認してみてください。)
つまり言語自体がある程度複雑性を持つことによって、 その言語によって記述されるプログラムは逆にシンプ ルになるのです。これは日本語という複雑な言語が俳 句という極めてシンプルな芸術作品を生み出すのに似 ています。もちろん、単に言語が複雑であればよいわ けではありませんが、Rubyの場合はプログラムがシン プルに記述できるような、バランスの取れた複雑さに なっています。(図1)
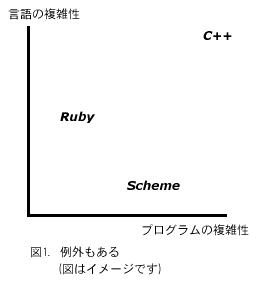
Rubyは純粋なオブジェクト指向言語です。「純粋」と いうのは、Rubyで扱う、数値や文字列や配列、といっ たすべてのデータはオブジェクトであるということで す。このため、Rubyはすべてのデータを統一的な方法 で操作することができます。
たとえば、文字列や配列の長さを知りたい時は、
str = "abcdefg" len = str.length ary = [1, 2, 3] len = ary.length
のように、共にlengthメソッドを使います。
また、整数の加算や文字列の連結は、
x = 1 + 2 x = "foo" + "bar"
のように共に+メソッドを使います。Rubyでは実は+ のような演算子もメソッドである点に注意してくださ い。(そのためユーザが再定義することができます。)
Perlの場合は、
print 1 + 2, "\n"; #=> 3 # +はデータを数値として扱う print 1 . 2, "\n"; #=> 12 # .はデータを文字列として扱う
のように適用する演算子によってデータの意味が変わ りますが、Rubyの場合は、
print 1 + 2, "\n"; #=> 3 # 数値に対する+は加算を行う print "1" + "2", "\n"; #=> 12 # 文字列に対する+は連結を行う
のようにデータ(オブジェクト)の種類(クラス)によっ て演算子の意味が変わります。対照的で面白いですね。
また、PerlやRubyは、「簡単なことは簡単に、複雑な こともそれなりにできる」ように設計されているので すが、Perlの場合はクラス定義は「複雑」な部類に入 るのに対し、Rubyの場合は「簡単」な部類に入ります。
以下はカウンタを実現するクラスの例です。
class Counter
# 初期化
def initialize
@value = 0
end
# 値をインクリメントする
def inc
@value += 1
end
# 現在の値を返す
def value
return @value
end
end
c = Counter.new
c.inc
c.inc
print c.value, "\n" # => 2
上のコードを見てわかる通り、Rubyのクラス定義は 非常にシンプルです。
ガーベージコレクションというのは「ごみ集め」とい う意味です。これは使われなくなったオブジェクトを 自動的に回収してくれる機能です。これによってRuby プログラマは面倒なメモリ管理から解放されます。
たとえば、次のコードでxはローカル変数です。
def foo x = Object.new .... end
したがって、xが指しているオブジェクトはfooの実行 が終わるとどこからも参照されなくなります。Rubyは このようなごみになったオブジェクトを自動的に検出 して回収してくれます。回収されたオブジェクトは後 でオブジェクトが生成される際に再利用されます。
通常、Rubyプログラマはガーベージコレクションのこ とを意識する必要はありません。それはプログラマで はなくRubyインタプリタの仕事だからです。しかし、 同時に、ガーベージコレクションは非常に重要な機能 でもあります。Rubyプログラマにとってガーベージコ レクションは空気のようなものだと言ってよいでしょ う。
Rubyは例外処理機能を持っています。
たとえば、ファイルをopenして何か書き込み処理をよ うとして失敗したとしましょう。
例外処理がない場合は、
f = open("/tmp/foo")
unless f
$stderr.print "failed to open file\n"
exit 1
end
if f.write("foo bar") == -1
$stderr.print "failed to write\n"
exit 1
end
のように、何か処理を行う度に戻り値をチェックして エラー時の処理を行う必要があります。
例外処理を使うと、
begin
f = open("/tmp/foo")
f.write("foo bar")
rescue
$stderr.print "failed to write file\n"
exit 1
end
のようにエラー時の処理をまとめて記述することがで きます。この場合、beginからrescueまでの処理で何 らかの例外が発生した場合、rescueからendまでのブ ロックが実行されます。
例外処理というと何とくなく面倒そうだと感じる方も いらっしゃるかもしれませんが、むしろ例外処理を使っ た方が楽に処理を記述することができます。ただし、 何でもかんでもrescueしてしまうとデバッグが困難に なる場合もありますので、注意が必要です。
イテレータという言葉にはあまり馴染みのない方も多 いかもしれません。C++のSTLにもイテレータはありま すが、Rubyのイテレータはまったく異なるものです。 イテレータは「繰り返すもの」という意味で、もとも とは繰り返しの制御を行うためのものです。たとえば、 配列の各要素に対して繰り返し処理を行いたい、とい うことはよくあります。たとえば、次のように書くこ とができます。
# filesは配列 for i in 0 .. files.length - 1 print files[i], "\n" end
このコードには二つ問題があります。一つは範囲を間 違える危険がある点です。Pascalプログラマは間違っ て次のように書いてしまうかもしれません。
for i in 1 .. files.length print files[i], "\n" end
もう一つはfilesを配列以外のものに置き換えた場合、 コードを書き直す必要があるという点です。たとえば、 filesがリンクトリストだったら以下のように記述す る必要があるでしょう。
l = files.first while l print l.value, "\n" l = l.next end
つまり、ユーザが各データ(配列やリンクトリスト)の 構造を知っていないと、「すべての要素について繰り 返す」という処理を行うことができないわけです。
一方、イテレータでは「すべての要素について繰り返 す」という処理を一般化して、次のように書くことが できます。
files.each do |file| print file, "\n" end
これはeachというイテレータの例です。eachはすべて の要素に対してdoからendまでのブロックを繰り返し ます。イテレータを使うと、繰り返しをユーザが制御 する必要がありません。そのため、範囲を間違えるよ うなこともありません。また、イテレータもメソッド の一種なので、操作対象(レシーバ)の種類(クラス)に よって動作が異なります。配列なら配列の各要素に対 して繰り返し、ファイルならファイルの各行に対して 繰り返します。したがって異なる種類のデータを統一 的に扱うことができます。
また、Rubyのイテレータの適用範囲は繰り返し処理に とどまりません。たとえば、次のようなイテレータも あります。
File.open(filename) do |f|
f.write("hello world\n")
end
このイテレータはファイルをオープンし、ブロックを 実行した後で、ファイルをクローズする、という処理 を行います。
Rubyのイテレータは繰り返しに特化したものではなく、 ブロックをパラメータとして与えることができるメソッ ドです。与えられたブロックの利用方法はイテレータ によって異なります。あるイテレータはブロックを繰 り返し実行するかもしれませんし、あるイテレータは 常に一回しか実行しないかもしれません。したがって イテレータという名前はあまり実情を反映していない のですが、歴史的理由や、他に適当な名前がないこと から、現在でもイテレータと呼ばれています。
ここでRubyのインストールについて簡単に説明してお きましょう。Rubyは様々な環境用にバイナリパッケー ジが提供されていますが、ここではオリジナルのソー スパッケージを利用してインストールする手順を説明 します。
まずパッケージを展開し、作成されたディレクトリに 移動します。
$ tar zxvf ruby-1.6.2.tar.gz $ cd ruby-1.6.2/
次にconfigureを実行し、環境のチェックを行います。
$ ./configure
作成されたMakefileを利用してコンパイルします。
$ make
あとはrootになってインストールするだけです。
# make install
configureではインストール先や、デフォルトの文字 コードなどをオプションで指定することができます。
$ ./configure --help
とすると各オプションの説明が出力されますので参考 にしてください。
それでは実際にRubyでCGIスクリプトを作成してみる ことにしましょう。リスト1[hello1.cgi]は単にHTML を出力するだけのCGIスクリプトです。
1行目はOSにこのスクリプトを実行するプログラムが /usr/bin/rubyであることを教えるおまじないです。 次にprintでへッダを出力しています(3行目)。そして、 それ以降はprintでHTMLを出力しているだけです(4行 目〜)。printしか使っていないので非常にシンプルで わかりやすいと思います。(その代りまったく面白味 もありませんが。)
リスト1ではprintを使って自前でへッダを出力してい ますが、このままではNPH-CGI(HTTPサーバが出力され たへッダをパーズして足りない情報を付加して*くれ ない*)やmod_ruby(ApacheというHTTPサーバにRubyイ ンタプリタを組み込んで高速にRubyスクリプトを実行 する仕組み)で動作しません。そのような場合にも自 前で必要な処理を行うこともできますが、cgiライブ ラリを使うとそれらの違いを吸収して必要な情報を出 力できるため、cgiライブラリの使用をお勧めします。
リスト2[hello2.cgi]はリスト1をcgiライブラリを使っ て書き直したものです。まず、cgiライブラリを requireしています(3行目)。requireは指定したライ ブラリ(この場合はcgi.rb、requireでは.rbを省略で きます)をロードします。次にCGIオブジェクトを生成 してcgiというローカル変数に代入しています(5行目)。 そして、headerメソッドを使ってへッダを出力してい ます(6〜7行目)。
あるクラスのオブジェクトを生成するには、
クラス名.new
とします。オブジェクトというのはプログラムで扱う 様々なデータで、クラスというのはオブジェクトの種 類です。
また、
オブジェクト.メソッド名(引数1, 引数2, ...)
で、そのオブジェクトに対するメソッド呼び出しを行い ます。メソッドというのは簡単に言えばオブジェクト に対する操作です。headerというメソッドはへッダを 文字列として返す、という操作を行います。
Rubyでは、プログラムはオブジェクトに対するメソッ ド呼び出しの組み合わせによって構成されます。とい うと何やら難しそうですが、プログラムはデータを操 作するものなので当り前ですね。ちなみに先程のprint やrequireも、実は対象となるオブジェクト(レシーバ と呼ばれます)と引数の括弧が省略されたメソッド呼 び出しです。
さて、リスト2に戻りましょう。headerに"type"と "charset"という2つのオプションを渡しています。 "type"にはContent-Type、"charset"には Content-Typeのcharsetパラメータの値を指定します。 この場合は、
Content-Type: text/html; charset=iso-8859-1
というへッダが返されます。
CGIクラスはへッダの出力の他にも様々な機能を持っ ています。たとえばCGIに対するパラメータを受け取っ てデコードする機能もその一つです。CGIにはフォー ム入力やURLによってパラメータを与えることができ ます。それらのパラメータはURLエンコードされた形 でCGIに渡されるため、CGIは与えられたデータを解析 してデコードする必要があります。CGIクラスは生成 時に渡されたデータを自動的にデコードして簡単にア クセスできるようにしてくれます。
リスト3[editname.html]はフォームの例です。 showname.cgiというCGIスクリプトにnameというパラ メータを渡します。showname.cgiのソースをリスト 4[showname.cgi]に示します。
nkfというライブラリをrequireしています(4行目)が、 これは漢字コードの変換を行うライブラリです。7行 目ではCGI#key?(「CGIクラスのkey?メソッド」の意味) を使ってnameというパラメータが与えられているかど うかチェックしています。与えられていた場合は、 cgi["name"][0]でnameパラメータの値を取り出し、 NKF.nkfで漢字コードをEUCに変換し、CGI.escapeHTML で、&や<などの特殊な文字をエスケープ(&などに 変換)しています。CGI.escapeHTMLはクラスに対して メソッドを呼び出しています。このようなメソッドは クラスメソッドとよばれ、オブジェクトを生成しなく ても呼び出すことができます。
cgi["name"]でなく、cgi["name"][0]としているのは、 cgi["name"]だと配列が返されるためです。なぜ配列 を返すようになっているかというと、nameというパラ メータが複数与えられる場合もあるからです。あとは、 リスト2と同じようにへッダとHTMLを出力しています。 異なるのはnameの値を出力している(18行目)点です。 Rubyでは、#{name}のように、#{}を使って文字列に変 数などの任意の式を埋め込むことができます。
が"太郎"の場合、
"<p>あなたの名前は太郎です。</p>\n"
となります。
CGIクラスにはHTMLを動的に生成する機能もあります。 リスト5[dir.cgi]はディレクトリのインデックスを生 成するCGIスクリプトです。CGI.newに"html4Tr"とい う引数を渡しています(5行目)が、これは生成する HTMLのバージョン(この場合はHTML 4.01 Transitional)を示します。次にCGI#outというイテレー タでへッダとボディを出力しています(6行目)。 CGI#outの引数はCGI#headerと同じで、ボティはブロッ クで渡します。たとえば、以下の例では"hello world"というプレーンテキストを出力します。
cgi.out("type" => "text/plain",
"charset" => "iso-8859-1") do
"hello " + "world"
end
リスト5ではCGI#outに渡すブロックで、CGIオブジェ クトを使ってHTMLを動的に生成しています(7行目〜)。 CGIオブジェクトは次のようにイテレータでHTMLの各 要素を生成します。
cgi.要素名("属性名" => "属性値", ...) do
要素の内容
end
たとえば、
cgi.a("href" => "http://www.ruby-lang.org/") do
"Rubyの公式ページ"
end
は、
<A href="http://www.ruby-lang.org/">Rubyの公式ページ</A>
のようなA要素を生成します。
リスト5ではCGI#htmlに"PRETTY" => trueというパラ メータを与えています(7行目)が、これは適当なとこ ろで改行を入れたりして生成されるHTMLを見やすくす るためです。
要素の内容を与えるブロックの中には他の要素を入れ ることもできます。複数の要素を入れる場合は+を使っ て連結します(10行目)。12行目から20行目ではUL要素 を生成していますが、この部分がこのスクリプトのポ イントになる部分です。Dir.foreachというディレク トリ内の各ファイル(の名前)についてブロックを繰り 返し実行するイテレータを利用して、ファイルのリス トを生成しています。CGI#ulに与えられたブロックの 値は最後のlist(19行目)の値になります。
この例のように、実行時にならないとどのような要素 を出力するのかわからない場合に、CGIクラスのHTML 生成機能を使うと非常に有効です。
CGIスクリプトを作成していると、複数のCGIスクリプ トで一つのセッションを実現したいということがよく あります。たとえば、ショッピングカートを実現する ことを考えてみましょう。この場合、CGIスクリプト はユーザが選択した商品を覚えておく必要があります。 そうでないと、いざ購入しようとした時にカートの中 には何も商品がないということになってしまいます。 これではぜんぜん儲かりませんね。
よく使われるのは、セッションに関する情報はサーバ 側で管理しておいて、クライアントにはそのセッショ ンを表すユニークなIDを渡す、という手法です。次に アクセスされた時にクライアントからそのIDを受け取 ることで、サーバに保持しておいたデータの中からそ のセッションに関する情報を拾い出すわけです。
問題は、クライアントにIDを渡し、再び受け取る方法 です。方法は二つあります。一つはフォームのhidden フィールドを使ってセッションIDを渡す方法で、もう 一つはクッキーを使う方法です。
幸い、Rubyでは、これらの方法を使ってセッション管 理を行う、cgi/sessionライブラリが標準で提供され ています。ただし、Ruby 1.6.2に含まれる cgi/sessionライブラリには問題があるので、CVSの 1.6系列(ruby_1_6ブランチ)の最新版のものを利用す るようにしてください。
cgi/sessionライブラリではCGI::Sessionオブジェク トを利用してセッション管理を行います。 CGI::Sessionオブジェクトを使ってデータを保存する には次のようにします。
require "cgi"
require "cgi/session"
cgi = CGI.new
session = CGI::Session.new(cgi)
session["address"] = "shugo@zetabits.co.jp"
print cgi.header("charset" => "iso-8859-1")
この場合"address"というキーで "shugo@zetabits.co.jp"というデータを保存していま す。クッキーを使う場合はCGI#headerやCGI#outを使っ てへッダを出力する必要がある点に注意してください。 フォームのhiddenフィールドを利用する場合は、 CGI#formを利用してフォームを出力する必要がありま す。その際GETメソッドを使用するとセッションIDが 外部に洩れる可能性がありますので、必ずPOSTメソッ ドを使用するようにしてください。
このように保存したデータを他のCGIスクリプトで取 り出すには次のようにします。
cgi = CGI.new session = CGI::Session.new(cgi) address = session["address"]
クッキーを使う場合、セッションは同じディレクトリ に置いたCGIスクリプト間でのみ共有されるので注意 してください。
このようにCGI::Sessionを使うと簡単にセッション管 理を行うことができます。ただ、一点だけ注意が必要 なのは、cgi/sessionではセッション情報を保存する ファイルのパーミッションが指定されていないため、 作成されるファイルのパーミッションはumaskの値に 依存するということです。たとえば、umaskが022なら ファイルのパーミッションは644になるので任意のユー ザがファイルを読むことができてしまいます。それで は困るという場合は、以下のようにCGI::Sessionオブ ジェクトを生成する前にumaskを設定してください。
File.umask(0066) session = CGI::Session.new(cgi)
eRubyとはHTMLなどの文書にRubyプログラムを埋め込 むための仕組みです。
CGIスクリプトではHTMLの一部だけを変更して出力す るというケースが多いのですが、eRubyを使うとその ようなケースで見やすいHTMLを書くことができます。
eRubyはとくにHTMLに特化していないので、HDMLや LaTexなどの他の文書に応用することもできます。
eRubyの処理系の一つであるerubyのインストール方法 を説明します。(eRubyにはerubyの他にもERbという Rubyによる実装があります。)
まずパッケージを展開し、作成されたディレクトリに 移動します。
$ tar zxvf eruby-0.1.3.tar.gz $ cd eruby-0.1.3/
次にMakefile.RBを実行し、Makefileを作成します。
$ ruby Makefile.RB --default-charset=utf-8
--default-charsetというオプションはerubyが出力す るContent-Typeのcharsetパラメータのデフォルト値 を指定します。ここではeuc-jpを指定しています。
あとはコンパイルしてインストールするだけです。
$ make # make install
erubyは、
$ eruby [オプション] <ファイル名>
のようにeRubyで記述されたファイルを指定して実行 することができます。指定可能なオプションは以下の 通りです。
デバッグフラグ($DEBUG)を設定する
漢字コード($KCODE)を指定する
動作モードを指定する
f: フィルタモード c: CGIモード n: NPH-CGIモード
Content-Typeのcharsetパラメータを指定する
CGIのへッダを出力しない
冗長モードにする
バージョン情報を表示して終了する
eRubyファイルの先頭に
#!/usr/bin/eruby -Ke -C euc-jp
のように書いておくと、
$ eruby foo.rhtml
のように実行された場合でも、erubyが先頭の行を解 析して、指定されたオプションを見てくれるので便利 です。
eRubyの文法、というとおおげさですが、eRubyファイ ルにRubyプログラムを埋め込むための形式について説 明します。
値を利用しないブロック
<% print "hello world" %>
のように'<%'と'%>'で囲まれたブロックはRubyプ ログラムとして実行され、その出力結果によって 置き換えられます。上の例では、
hello world
という変換結果となります。
値を利用するブロック
1 + 2 は <%= 1 + 2 %> です
のように'<%'の後に'='が続く場合は、そのブロッ クをRubyプログラムとして評価した値によって置 き換えられます。上の例では
1 + 2 は 3 です
という変換結果になります。
コメント
<%# これはコメントです %>
のように'<%'の後に#が続く場合は、コメントと して無視(削除)されます。上の例では出力結果は 空行になります。
一行プログラム
% print "hello world\n"
のように%で始まる行は、一行のRubyプログラム として実行され、その出力結果で置き換えられま す。
<% x = 1 + 2 %>
では、'%>'の後の改行が変換結果に出力されます が、
% x = 1 + 2
の場合は、改行が出力されないので、何も出力し たくない処理を行う場合に便利でしょう。
eRubyをCGIで利用するには以下のような二通りの方法 があります。
eRubyファイル自体をCGIプログラムとして利用する
eRubyで記述されたファイルの先頭行に、
#!/usr/bin/eruby
と記述して実行権限を与えると、通常のRubyスク リプトと同じようにCGIスクリプトとして動作さ れることができます。
erubyをCGIプログラムとして利用する
erubyをCGIプログラムとして実行し、PATH_INFO でeRubyファイルを指定してやることも可能です。
たとえば、/cgi-bin/erubyにerubyを置き、 /~user/hello.rhtmlにeRubyファイルを置いた場 合は、
http://your.host.name/cgi-bin/eruby/~user/hello.rhtml
のようにアクセスすることでeRubyファイルの変 換結果を表示されることができます。
Apacheの場合は、httpd.confに、
AddType application/x-httpd-eruby .rhtml Action application/x-httpd-eruby /cgi-bin/eruby
と記述することで、
http://your.host.name/~user/hello.rhtml
のようにアクセスされた場合に/cgi-bin/erubyに よって実行させることもできます。
いずれの場合も、とくに指定しないかぎり、へッダは erubyが出力してくれます。
また、mod_rubyでeRubyファイルを扱うこともできま す。詳しくはhttp://www.modruby.net/を参照してく ださい。
erubyの挙動を制御するためにERubyというモジュール が提供されています。このモジュールには二つの機能 があります。
一つは、
<%
require "cgi"
ERuby.noheader = true
cgi = CGI.new
print cgi.header("type" => "text/x-hdml",
"charset" => "shift_jis")
%>
のようにerubyのへッダ出力を抑制させる機能です。 これは、コマンドラインオプションの--noheaderと 同じ効果を持ちます。
もう一つは、
<% ERuby.charset = "shift_jis" %>
のようにcharsetパラメータの値を指定する機能です。 これもコマンドラインオプションの-Cと同じ効果を持 ちます。
さて、ここでeRubyを使って、ちょっと実用的なCGIプ ログラムを作成してみましょう。題材にするのはメー ル閲覧プログラムです。このプログラムはIMAPサーバ に接続してメールを読むためのプログラムです。とい うとと難しそうですが、Rubyでは標準でIMAPクライア ント用のライブラリが提供されているので、このよう なプログラムも比較的簡単に作ることができます。
このプログラムは以下のファイルによって構成されま す。
設定を記述するファイル
各スクリプトに共通の処理を記述したライブラリ
ログイン用のフォーム
メールボックスの一覧を表示するスクリプト
メール一覧を表示するスクリプト
メールの内容を表示するスクリプト
ログアウトを行うスクリプト
各ファイルについて順に説明して行きましょう。
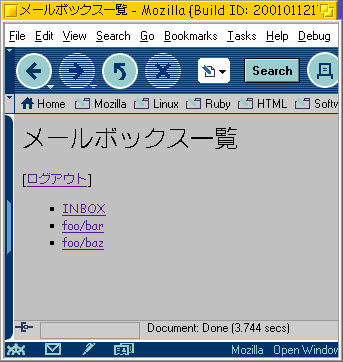
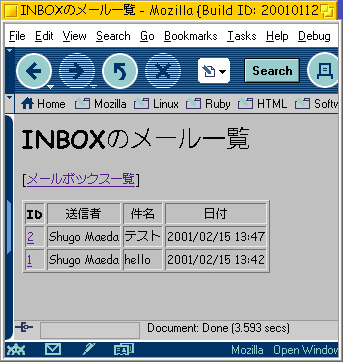
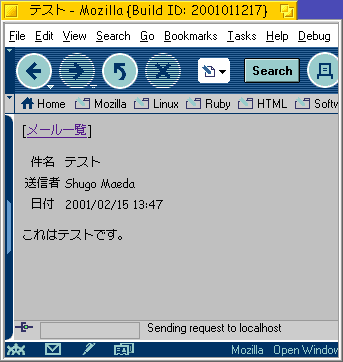
このファイルは設定を記述するためのファイルです。 HOSTという定数にIMAPサーバのホスト名あるいはIPア ドレスを、SESSION_DIRという定数にセッションファ イルを置くディレクトリのパスを指定します。
SESSION_DIRはCGIプログラムが実行されるユーザの権 限で書き込みができるディレクトリでなければなりま せん。/tmpでも構いませんが、cronでセッションファ イルをexpireするスクリプトを動かすような場合を考 えると、別のディレクトリにしておいた方がよいでしょ う。
util.rbでは5つの関数(メソッド)を定義しています。
errorはエラーメッセージを出力してスクリプトの実 行を終了する関数です(5行目)。HTMLをprintしている だけですが、複数行の文字列をスクリプトに埋め込む ためにヒアドキュメントというものを使っています。 <<EOFからEOFまでの間(6〜19行目)が一つの文字列と して出力されます。
open_sessionはセッション管理をサポートするための イテレータです。CGI::Sessionオブジェクトを生成し (26〜28行目)、yieldで与えられたブロックを実行(34 行目)した後で、CGI::Sessionをcloseして(38行目)、 へッダを出力します(39〜40行目)。イテレータを定義 する時には、このように与えられたブロックを実行し たい所でyieldを使用します。yeildに与えた引数はブ ロックに渡されます。
CGI::Sessionオブジェクトを生成する時のパラメータ で、ファイルを生成するディレクトリ("tmpdir")と、 新しいセッションかどうか("new_session")を指定し ています(26〜28行目)が、CGIに"user"というパラメー タが与えられていた場合は新しいセッションであると 判断しています(24行目)。これはログイン用のフォー ムで"user"というパラメータが与えられるためです。
新しいセッションでない場合に、セッション情報から "user"というキーで値を取り出すことができない場合 は、すでにセッションが無効になっている(ログアウ トされている)と判断してエラーメッセージを出して 終了しています(29〜32行目)。
format_from、format_subject、format_dateはメール のFromやSubjectや日付の情報をフォーマットする関 数です。とくに難しいことはしていませんので内容を 見ておいてください。
login.htmlはログイン用のフォームです。ユーザ (user)、パスワード(password)、認証方式 (auth_type)という3つのパラメータを入力できるよう になっています。
from要素のaction属性にはmailboxes.rhtmlが指定さ れており、ログイン後はメールボックスの一覧を表示 するようになっています。
mailboxes.rhtmlはIMAPサーバ上のメールボックスの 一覧を表示するCGIスクリプトで、eRubyで記述されて います。$mailboxesというグローバル変数にメールボッ クスの名前の配列を格納し、HTMLの中にその名前を埋 め込んでいます。
まず、open_sessionを使ってCGI::Sessionオブジェク トを生成し、CGIにパラメータが与えられている場合 (login.htmlから呼ばれた場合)には、CGI::Sessionオ ブジェクトに値を保存しています(9〜14行目)。
そして、Net::IMAPオブジェクトを生成し、セッショ ン情報をもとに認証を行っています(15〜16行目)。
メールボックスの一覧はNet::IMAP#listというメソッ ドで得ています(18行目)。listメソッドはメールボッ クスの情報を表すNet::IMAP::MailboxListオブジェク トの配列を返します。
このリストから選択できるメールボックスの名前だけ を取り出し(19〜23行目)、重複するものを取り除いて います(24行目)。
これでメールボックスの名前のリストを得ることがで きたので、後はHTMLに展開するだけです(36〜28行目)。 この部分はちょっとわかりにくいかもしれませんが、 次のようなRubyスクリプトと同じ意味だと考えると、 理解しやすいと思います。
for mbox in $mailboxes
print '<li><a href="summary.rhtml?mailbox=#{mbox}">#{mbox}'
end
summary.rhtmlとmessage.rhtmlはIMAPに関係する部分 以外はあまりmailboxes.rhtmlと変わりませんので、 説明を省略します。
logout.rhtmlはセッションファイルを削除してそのセッ ションを無効にします。実際には CGI::Session#deleteを呼んでいるだけです(9行目)。
さて、駆け足でRubyによるCGIプログラミングについ て説明して来ましたがいかがでしたでしょうか。説明 が不十分な面もあると思いますが、Ruby自体について は書籍が何冊か出版されていますので参考にしてみて ください。